
[RNN] RNN là gì?
Bài giới thiệu RNN này được dịch lại từ trang blog WILDML.
Mạng nơ-ron hồi quy (RNN - Recurrent Neural Network) là một thuật toán được chú ý rất nhiều trong thời gian gần đây bởi các kết quả tốt thu được trong lĩnh vực xử lý ngôn ngữ tự nhiên.
Tuy nhiên, ta vẫn thiếu các bài viết giải thích tường tận về cách hoạt động, cách xây dựng mạng RNN, nên trong chuỗi bài viết này tôi sẽ viết về các vấn đề đó. Chuỗi bài viết được chia thành 4 phần sau:
- 1. Giới thiệu RNN (bài viết này)
- 2. Cài đặt RNN với Python và Theano
- 3. Tìm hiểu về giải thuật BPTT và vấn đề mất mát đạo hàm
- 4. Cài đặt GRU/LSTM
Mục lục
1. Mô hình ngôn ngữ
Ok, giờ tôi sẽ trình bày về mô hình ngôn ngữ dựa trên RNN. Ứng dụng của mô hình ngôn ngữ gồm 2 dạng. Một là đánh giá độ chính xác của một câu dựa theo mức độ tương tự của chúng trên thực tế. Việc đánh giá này giúp ta ước lượng được độ chính xác của văn phạm lẫn ngữ nghĩa của một câu. Những mô hình này thường được ứng dụng trong các hệ thống dịch máy (Machine Translation). Hai là tự động sinh văn bản (tôi cho rằng ứng dụng này hấp dẫn hơn). Ví dụ huấn luyện mô hình với các tác phẩm của Shakespeare có thể cho phép ta sinh ra các câu từ tựa như cách Shakespeare viết. Ngoài ra, nếu có thời gian, các bạn có thể tham khảo thêm bài viết thú vị này (tiếng Anh) của Andrej Karpathy về khả năng của các mô hình ngôn ngữ mức độ từ vựng.
Bài viết này dành cho các bạn đã biết cơ bản về mạng nơ-rơn (Neural Network), nếu bạn chưa biết về mạng nơ-ron thì hãy đọc bài viết Cài đặt mạng nơ-ron cơ bản. Bài viết đó sẽ giúp bạn có cái nhìn cơ bản về ý tưởng và cách xây dựng một mạng nơ-ron cơ bản - mạng nơ-ron phi hồi quy.
2. Mạng hồi quy RNN là gì?
Ý tưởng chính của RNN (Recurrent Neural Network) là sử dụng chuỗi các thông tin. Trong các mạng nơ-ron truyền thống tất cả các đầu vào và cả đầu ra là độc lập với nhau. Tức là chúng không liên kết thành chuỗi với nhau. Nhưng các mô hình này không phù hợp trong rất nhiều bài toán. Ví dụ, nếu muốn đoán từ tiếp theo có thể xuất hiện trong một câu thì ta cũng cần biết các từ trước đó xuất hiện lần lượt thế nào chứ nhỉ? RNN được gọi là hồi quy (Recurrent) bởi lẽ chúng thực hiện cùng một tác vụ cho tất cả các phần tử của một chuỗi với đầu ra phụ thuộc vào cả các phép tính trước đó. Nói cách khác, RNN có khả năng nhớ các thông tin được tính toán trước đó. Trên lý thuyết, RNN có thể sử dụng được thông tin của một văn bản rất dài, tuy nhiên thực tế thì nó chỉ có thể nhớ được một vài bước trước đó (ta cùng bàn cụ thể vấn đề này sau) mà thôi. Về cơ bản một mạng RNN có dạng như sau:
 A recurrent neural network and the unfolding in time of the computation involved in its forward computation. Source: Nature
A recurrent neural network and the unfolding in time of the computation involved in its forward computation. Source: NatureMô hình trên mô tả phép triển khai nội dung của một RNN. Triển khai ở đây có thể hiểu đơn giản là ta vẽ ra một mạng nơ-ron chuỗi tuần tự. Ví dụ ta có một câu gồm 5 chữ “Đẹp trai lắm gái theo”, thì mạng nơ-ron được triển khai sẽ gồm 5 tầng nơ-ron tương ứng với mỗi chữ một tầng. Lúc đó việc tính toán bên trong RNN được thực hiện như sau:
- $ \color{blue}x_t $ là đầu vào tại bước $ \color{blue}t $. Ví dụ, $ \color{deeppink}x_1 $ là một vec-tơ one-hot tương ứng với từ thứ 2 của câu (trai).
$ \color{blue}s_t $ là trạng thái ẩn tại bước $ \color{blue}t $. Nó chính là bộ nhớ của mạng. $ \color{blue}s_t $ được tính toán dựa trên cả các trạng thái ẩn phía trước và đầu vào tại bước đó: $ \color{blue}s_t = f(U x_t + W s_{t-1} ) $. Hàm $ \color{blue}f $ thường là một hàm phi tuyến tính như tang hyperbolic (tanh) hay ReLu. Để làm phép toán cho phần tử ẩn đầu tiên ta cần khởi tạo thêm $ \color{deeppink}s_{-1} $, thường giá trị khởi tạo được gắn bằng
0.$ \color{blue}o_t $ là đầu ra tại bước $ \color{blue}t $. Ví dụ, ta muốn dự đoán từ tiếp theo có thể xuất hiện trong câu thì $ \color{blue}o_t $ chính là một vec-tơ xác xuất các từ trong danh sách từ vựng của ta: $ \color{blue}o_t = \mathrm{softmax}(V s_t) $
3. Khả năng của RNN
Trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP - Natural Language Processing), đã ghi nhận được nhiều thành công của RNN cho nhiều vấn đề khác nhau. Tại thời điểm này, tôi muốn đề cập tới một mô hình phổ biến nhất được sử dụng của RNN là LSTM. LSTM (Long Short-Term Memory) thể hiện được sự ưu việt ở điểm có thể nhớ được nhiều bước hơn mô hình RNN truyền thống. Nhưng bạn không cần phải quá lo lắng vì LSTM về cơ bản giống với cấu trúc của RNN truyền thống, chúng chỉ khác nhau ở cách tính toán của các nút ẩn. Chúng ta sẽ cùng xem chi tiết hơn về LSTM trong bài viết tiếp theo. Còn giờ, ta cùng nhau xem một vài ứng dụng của RNN trong xử lý ngôn ngữ tự nhiên dưới đây.
3.1. Mô hình hóa ngôn ngữ và sinh văn bản
Mô hình ngôn ngữ cho phép ta dự đoán được xác xuất của một từ nào đó xuất hiện sau một chuỗi các từ đi liền trước nó. Do có khả năng ước lượng được độ tương tự của các câu nên nó còn được ứng dụng cho việc dịch máy. Một điểm lý thú của việc có thể dự đoán được từ tiếp theo là ta có thể xây dựng được một mô hình tự sinh từ cho phép máy tính có thể tự tạo ra các văn bản mới từ tập mẫu và xác xuất đầu ra của mỗi từ. Vậy nên, tùy thuộc vào mô hình ngôn ngữ mà ta có thể tạo ra được nhiều văn bản khác nhau khá là thú vị phải không. Trong mô hình ngôn ngữ, đầu vào thường là một chuỗi các từ (được mô tả bằng vec-tơ one-hot) và đầu ra là một chuỗi các từ dự đoán được. Khi huấn luyện mạng, ta sẽ gán $ \color{blue}o_t = x_{t+1} $ vì ta muốn đầu ra tại bước $ \color{blue}t $ chính là từ tiếp theo của câu.
Dưới đây là một vài nghiên cứu về mô hình hoá ngôn ngữ và sinh văn bản:
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
3.2. Dịch máy
Dịch máy (Machine Translation) tương tự như mô hình hóa ngôn ngữ ở điểm là đầu vào là một chuỗi các từ trong ngôn ngữ nguồn (ngôn ngữ cần dịch - ví dụ là tiếng Việt). Còn đầu ra sẽ là một chuỗi các từ trong ngôn ngữ đích (ngôn ngữ dịch - ví dụ là tiếng Anh). Điểm khác nhau ở đây là đầu ra của ta chỉ xử lý sau khi đã xem xét toàn bộ chuỗi đầu vào. Vì từ dịch đầu tiên của câu dịch cần phải có đầy đủ thông tin từ đầu vào cần dịch mới có thể suy luận được.
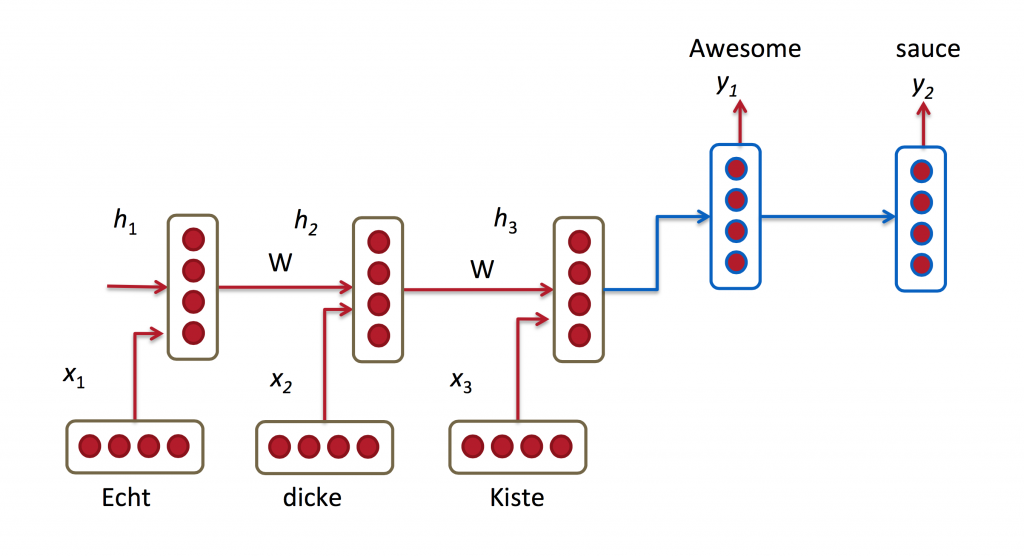 RNN for Machine Translation. Image Source: http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdf
RNN for Machine Translation. Image Source: http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdfDưới đây là một vài nghiên cứu về dịch máy:
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
3.3. Nhận dạng giọng nói
Đưa vào một chuỗi các tín hiệu âm thanh, ta có thể dự đoán được chuỗi các đoạn ngữ âm đi kèm với xác xuất của chúng.
Dưới đây là một vài nghiên cứu về nhận dạng giọng nói:
3.4. Mô tả hình ảnh
Cùng với ConvNet, RNN được sử dụng để tự động tạo mô tả cho các ảnh chưa được gán nhãn. Sự kết hợp này đã đưa ra được các kết quả khá kinh ngạc. Ví dụ như các ảnh dưới đây, các mô tả sinh ra có mức độ chính xác và độ tường tận khá cao.
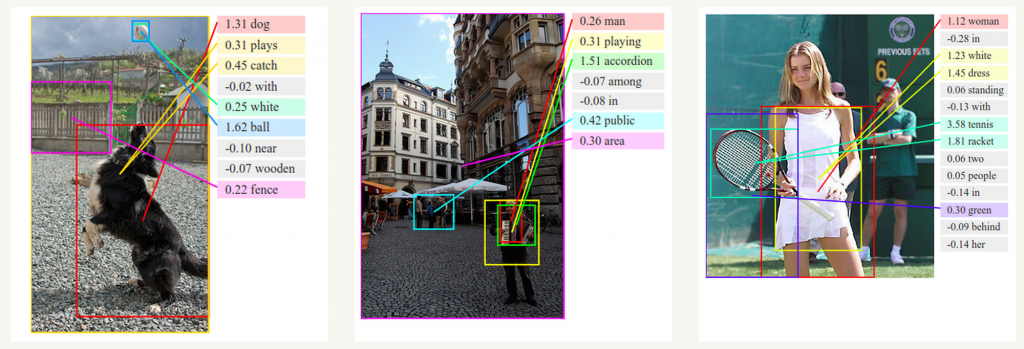 Deep Visual-Semantic Alignments for Generating Image Descriptions. Source: http://cs.stanford.edu/people/karpathy/deepimagesent/
Deep Visual-Semantic Alignments for Generating Image Descriptions. Source: http://cs.stanford.edu/people/karpathy/deepimagesent/4. Huấn luyện RNN
Huấn luyện mạng RNN cũng tương tự như các mạng nơ-ron truyền thống, tuy nhiên giải thuật lan truyền ngược (backpropagation) phải thay đổi một chút. Đạo hàm tại mỗi đầu ra phụ thuộc không chỉ vào các tính toán tại bước đó, mà còn phụ thuộc vào các bước trước đó nữa, vì các tham số trong mạng RNN được sử dụng chung cho tất cả các bước trong mạng. Ví dụ, để tính đạo hàm tại $ \color{deeppink}t = 4 $ ta phải lan truyền ngược cả 3 bước phía trước rồi cộng tổng đạo hàm của chúng lại với nhau. Việc tính đạo hàm kiểu này được gọi là lan truyền ngược liên hồi (BPTT - Backpropagation Through Time). Nếu giờ bạn chưa thể hiểu được BPTT thế nào thì cũng đừng lo sợ vì trong bài sau ta sẽ xem xét cụ thể nó là gì sau. Còn giờ, chỉ cần nhớ rằng với các bước phụ thuộc càng xa thì việc học sẽ càng khó khăn hơn vì sẽ xuất hiện vấn đề hao hụt/bùng nổ (vanishing/exploding) của đạo hàm. Có một vài phương pháp được đề xuất để giải quyết vấn đề này và các kiểu mạng RNN hiện nay đã được thiết kế để triệt tiêu bớt chúng như LSTM chẳng hạn.
5. RNN mở rộng
Trong nhiều năm, các nhà nghiên cứu đã phát triển nhiều kiểu RNN tinh vi để xử lý các nhược điểm của mô hình RNN truyền thống. Chúng ta sẽ xem chi tiết một vài mô hình đó ở các bài viết sau, còn ở bài này, tôi chỉ giới thiệu ngắn ngọn 2 mô hình dưới đây.
5.1. RNN 2 chiều
Ở mô hình RNN 2 chiều (Bidirectional RNN), đầu ra tại bước $ \color{blue}t $ không những phụ thuộc vào các phần tử phía trước mà còn phụ thuộc cả vào các phần tử phía sau. Ví dụ, để dự đoán từ còn thiếu trong câu, thì việc xem xét cả phần trước và phần sau của câu là cần thiết. Vì vậy, ta có thể coi mô hình là việc chồng 2 mạng RNN ngược hướng nhau lên nhau. Lúc này đầu ra được tính toán dựa vào cả 2 trạng thái ẩn của 2 mạng RNN ngược hướng này.
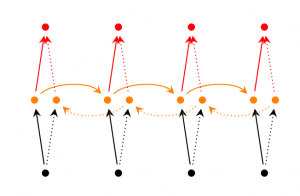 Bidirectional RNNs
Bidirectional RNNs5.2. RNN (2 chiều) sâu
RNN sâu (Deep (Bidirectional) RNN) cũng tương tự như RNN 2 chiều, nhưng khác nhau ở chỗ chúng chứa nhiều tầng ẩn ở mỗi bước. Trong thực tế, chúng giúp cho việc học ở mức độ cao hơn, tuy nhiên ta cũng cần phải có nhiều dữ liệu huấn luyện hơn.
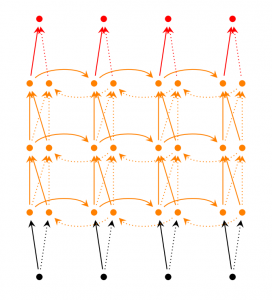 Deep (Bidirectional) RNNs
Deep (Bidirectional) RNNs5.3. Mạng LSTM
Gần đây, mạng LSTM mà ta có đề cập một chút phía trên được chú ý và sử dụng khá phổ biến. Về cơ bản mô hình của LSTM không khác mô hình truyền thống của RNN, nhưng chúng sử dụng hàm tính toán khác ở các trạng thái ẩn. Bộ nhớ của LSTM được gọi là tế bào (Cell) và bạn có thể tưởng tượng rằng chúng là các hộp đen nhận đầu vào là trạng thái phía trước $ \color{blue}h_{t-1} $ và đầu vào hiện tại $ \color{blue}x_t $. Bên trong hộp đen này sẽ tự quyết định cái gì cần phải nhớ và cái gì sẽ xoá đi. Sau đó, chúng sẽ kết hợp với trạng thái phía trước, nhớ hiện tại và đầu vào hiện tại. Vì vậy mà ta ta có thể truy xuất được quan hệ của các từ phụ thuộc xa nhau rất hiệu quả. Có thể khi mới làm quen với LSTM thì chúng hơi khó hiểu đôi chút, nhưng nếu bạn có hứng thú thì hãy xem bài viết xuất sắc này (bản dịch tại đây).
6. Kết luận
Okey, được rồi, tôi hi vọng là bạn đã hiểu cơ bản về RNN và khả năng của chúng.
Trong bài viết tiếp theo, chúng ta sẽ cài đặt phiên bản đầu tiên của mô hình ngôn ngữ RNN sử dụng Python
và Theano.
Giờ nếu bạn có thắc mắc gì thì có thể để lại câu hỏi ở phía dưới nhé!
