
[NN] Mạng nơ-ron nhân tạo - Neural Networks
Mạng nơ-ron nhân tạo (Neural Network - NN) là một mô hình lập trình rất đẹp lấy cảm hứng từ mạng nơ-ron thần kinh. Kết hợp với các kĩ thuật học sâu (Deep Learning - DL), NN đang trở thành một công cụ rất mạnh mẽ mang lại hiệu quả tốt nhất cho nhiều bài toán khó như nhận dạng ảnh, giọng nói hay xử lý ngôn ngữ tự nhiên.
Trong bài này, ta sẽ cùng tìm hiểu và cài đặt một NN cơ bản để làm nền tảng cho các bài về học sâu tiếp theo.
Mục lục
1. Perceptrons
1.1. Perceptron cơ bản
Một mạng nơ-ron được cấu thành bởi các nơ-ron đơn lẻ được gọi là các perceptron. Nên trước tiên ta tìm hiểu xem perceptron là gì đã rồi tiến tới mô hình của mạng nơ-ron sau. Nơ-ron nhân tạo được lấy cảm hứng từ nơ-ron sinh học như hình mô tả bên dưới:
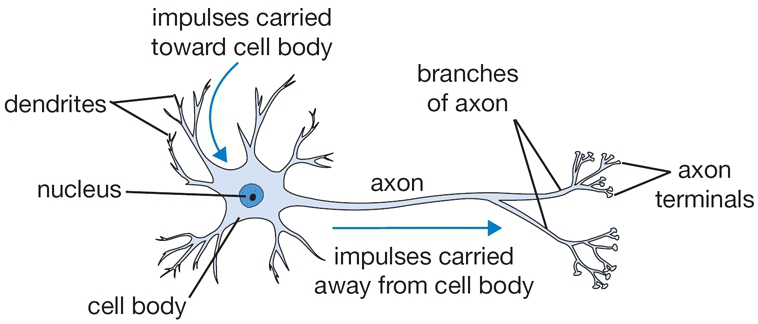 Nơ-ron sinh học. Source: https://cs231n.github.io/
Nơ-ron sinh học. Source: https://cs231n.github.io/Như hình trên, ta có thể thấy một nơ-ron có thể nhận nhiều đầu vào và cho ra một kết quả duy nhất. Mô hình của perceptron cũng tương tự như vậy:
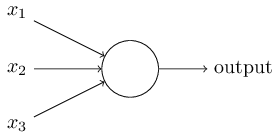 perceptron
perceptronMột perceptron sẽ nhận một hoặc nhiều đầu $\mathbf{x}$ vào dạng nhị phân và cho ra một kết quả $o$ dạng nhị phân duy nhất. Các đầu vào được điều phối tầm ảnh hưởng bởi các tham số trọng lượng tương ứng $\mathbf{w}$ của nó, còn kết quả đầu ra được quyết định dựa vào một ngưỡng quyết định $b$ nào đó:
$$ o = \begin{cases} 0 &\text{if }\displaystyle\sum_iw_ix_i \le \text{threshold} \cr 1 &\text{if }\displaystyle\sum_iw_ix_i > \text{threshold} \end{cases} $$
Đặt $b=-\text{threshold}$, ta có thể viết lại thành: $$ o = \begin{cases} 0 &\text{if }\displaystyle\sum_iw_ix_i + b \le 0 \cr 1 &\text{if }\displaystyle\sum_iw_ix_i + b > 0 \end{cases} $$
Để dễ hình dung, ta lấy ví dụ việc đi nhậu hay không phụ thuộc vào 4 yếu tố sau:
- 1. Trời có nắng hay không?
- 2. Có hẹn trước hay không?
- 3. Vợ có vui hay không?
- 4. Bạn nhậu có ít khi gặp được hay không?
Thì ta coi 4 yếu tố đầu vào là $x_1, x_2, x_3, x_4$ và nếu $o=0$ thì ta không đi nhậu còn $o=1$ thì ta đi nhậu. Giả sử mức độ quan trọng của 4 yếu tố trên lần lượt là $w_1=0.05, w_2=0.5, w_3=0.2, w_4=0.25$ và chọn ngưỡng $b=-0.5$ thì ta có thể thấy rằng việc trời nắng có ảnh hưởng chỉ 5% tới quyết định đi nhậu và việc có hẹn từ trước ảnh hưởng tới 50% quyết định đi nhậu của ta.
Nếu gắn $x_0=1$ và $w_0=b$, ta còn có thể viết gọn lại thành: $$ o = \begin{cases} 0 &\text{if }\mathbf{w}^{\intercal}\mathbf{x} \le 0 \cr 1 &\text{if }\mathbf{w}^{\intercal}\mathbf{x} > 0 \end{cases} $$
1.2. Sigmoid Neurons
Với đầu vào và đầu ra dạng nhị phân, ta rất khó có thể điều chỉnh một lượng nhỏ đầu vào để đầu ra thay đổi chút ít, nên để linh động, ta có thể mở rộng chúng ra cả khoảng $[0, 1]$. Lúc này đầu ra được quyết định bởi một hàm sigmoid $\sigma(\mathbf{w}^{\intercal}\mathbf{x})$. Như các bài trước đã đề cập thì hàm sigmoid có công thức: $$ \sigma(z) = \dfrac{1}{1+e^{-z}} $$
Đồ thị của hàm này cũng cân xứng rất đẹp thể hiện được mức độ công bằng của các tham số:
 Sigmoid Function
Sigmoid FunctionĐặt $z = \mathbf{w}^{\intercal}\mathbf{x}$ thì công thức của perceptron lúc này sẽ có dạng: $$ o = \sigma(z) = \dfrac{1}{1+\exp(-\mathbf{w}^{\intercal}\mathbf{x})} $$
Tới đây thì ta có thể thấy rằng mỗi sigmoid neuron cũng tương tự như một bộ phân loại tuyến tính (logistic regression) bởi xác suất $P(y_i=1|x_i;\mathbf{w})=\sigma(\mathbf{w}^{\intercal}\mathbf{x})$.
Thực ra thì ngoài hàm sigmoid ra, ta còn có thể một số hàm khác như $\tanh$, $\text{ReLU}$ để thay thế hàm sigmoid bởi dạng đồ thị của nó cũng tương tự như sigmoid. Một cách tổng quát, hàm perceptron được biểu diễn qua một hàm kích hoạt (activation function) $f(z)$ như sau: $$ o = f(z) = f(\mathbf{w}^{\intercal}\mathbf{x}) $$
Bằng cách biểu diễn như vậy, ta có thể coi neuron sinh học được thể hiện như sau:
 Mô hình Nơ-ron. . Source: https://cs231n.github.io/
Mô hình Nơ-ron. . Source: https://cs231n.github.io/Một điểm cần lưu ý là các hàm kích hoạt buộc phải là hàm phi tuyến. Vì nếu nó là tuyến tính thì khi kết hợp với phép toán tuyến tính $\mathbf{w}^{\intercal}\mathbf{x}$ thì kết quả thu được cũng sẽ là một thao tác tuyến tính dẫn tới chuyện nó trở nên vô nghĩa.
2. Kiến trúc mạng NN
Mạng NN là sự kết hợp của của các tầng perceptron hay còn được gọi là perceptron đa tầng (multilayer perceptron) như hình vẽ bên dưới:
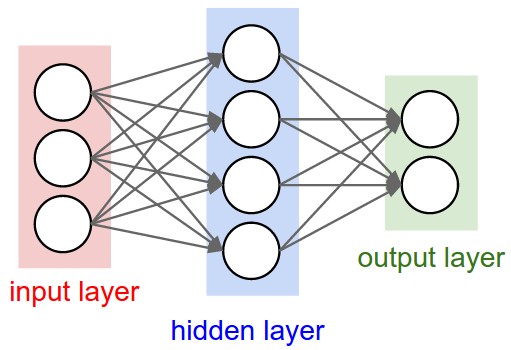 Neural Network. . Source: https://cs231n.github.io/
Neural Network. . Source: https://cs231n.github.io/Một mạng NN sẽ có 3 kiểu tầng:
- Tầng vào (input layer): Là tầng bên trái cùng của mạng thể hiện cho các đầu vào của mạng.
- Tầng ra (output layer): Là tầng bên phải cùng của mạng thể hiện cho các đầu ra của mạng.
- Tầng ẩn (hidden layer): Là tầng nằm giữa tầng vào và tầng ra thể hiện cho việc suy luận logic của mạng.
Lưu ý rằng, một NN chỉ có 1 tầng vào và 1 tầng ra nhưng có thể có nhiều tầng ẩn.
 NN - 2 hidden layer. . Source: https://cs231n.github.io/
NN - 2 hidden layer. . Source: https://cs231n.github.io/Trong mạng NN, mỗi nút mạng là một sigmoid nơ-ron nhưng hàm kích hoạt của chúng có thể khác nhau. Tuy nhiên trong thực tế người ta thường để chúng cùng dạng với nhau để tính toán cho thuận lợi.
Ở mỗi tầng, số lượng các nút mạng (nơ-ron) có thể khác nhau tuỳ thuộc vào bài toán và cách giải quyết. Nhưng thường khi làm việc người ta để các tầng ẩn có số lượng nơ-ron bằng nhau. Ngoài ra, các nơ-ron ở các tầng thường được liên kết đôi một với nhau tạo thành mạng kết nối đầy đủ (full-connected network). Khi đó ta có thể tính được kích cỡ của mạng dựa vào số tầng và số nơ-ron. Ví dụ ở hình trên ta có:
- $4$ tầng mạng, trong đó có $2$ tầng ẩn
- $3+4*2+1=12$ nút mạng
- $(3*4+4*4+4*1)+(4+4+1)=41$ tham số
3. Lan truyền tiến
Như bạn thấy thì tất cả các nốt mạng (nơ-ron) được kết hợp đôi một với nhau theo một chiều duy nhất từ tầng vào tới tầng ra. Tức là mỗi nốt ở một tầng nào đó sẽ nhận đầu vào là tất cả các nốt ở tầng trước đó mà không suy luận ngược lại. Hay nói cách khác, việc suy luận trong mạng NN là suy luận tiến (feedforward):
$$ \begin{aligned} z^{(l+1)}_i &= \displaystyle\sum_{j=1}^{n^{(l)}} w^{(l+1)}_{ij}a^{(l)}_j + b^{(l+1)}_i \cr a_i^{(l+1)} &= f\big(z^{(l+1)}_i\big) \end{aligned} $$
Trong đó, $n^{(l)}$ số lượng nút ở tầng $l$ tương ứng và $a^{(l)}_j$ là nút mạng thứ $j$ của tầng $l$. Còn $w^{(l+1)}_{ij}$ là tham số trọng lượng của đầu vào $a^{(l)}_j$ đối với nút mạng thứ $i$ của tầng $l+1$ và $b^{(l+1)}_i$ là độ lệch (bias) của nút mạng thứ $i$ của tầng $l+1$. Đầu ra của nút mạng này được biểu diễn bằng $a_i^{(l+1)}$ ứng với hàm kích hoạt $f(z_i)$ tương ứng.
Riêng với tầng vào, thông thường $\mathbf{a}^{(1)}$ cũng chính là các đầu vào $\mathbf{x}$ tương ứng của mạng.
Để tiện tính toán, ta coi $a^{(l)}_0$ là một đầu vào và $w^{(l+1)}_{i0}=b^{(l+1)}_i$ là tham số trọng lượng của đầu vào này. Lúc đó ta có thể viết lại công thức trên dưới dạng véc-tơ:
$$ \begin{aligned} z^{(l+1)}_i &= \mathbf{w}^{(l+1)}_i\cdot\mathbf{a}^{(l)} \cr a_i^{(l+1)} &= f\big(z^{(l+1)}_i\big) \end{aligned} $$
Nếu nhóm các tham số của mỗi tầng thành một ma trận có các cột tương ứng với tham số mỗi nút mạng thì ta có thể tính toán cho toàn bộ các nút trong một tầng bằng véc-tơ: $$ \begin{aligned} \mathbf{z}^{(l+1)} &= \mathbf{W}^{(l+1)}\cdot\mathbf{a}^{(l)} \cr \mathbf{a}^{(l+1)} &= f\big(\mathbf{z}^{(l+1)}\big) \end{aligned} $$
4. Học với mạng NN
Cũng tương tự như các bài toán học máy khác thì quá trình học vẫn là tìm lấy một hàm lỗi để đánh giá và tìm cách tối ưu hàm lỗi đó để được kết quả hợp lý nhất có thể. Như đã đề cập mỗi nút mạng của NN có thể coi là một bộ phân loại (logistic regression) có hàm lỗi là:
$$ J(\mathbf{W}) = -\frac{1}{m}\sum_{i=1}^m\Bigg(y^{(i)}\log\Big(\sigma^{(i)}\Big)+\Big(1-y^{(i)}\Big)\log\Big(1-\sigma^{(i)}\Big)\Bigg) $$
Trong đó, $m$ là số lượng dữ liệu huấn luyện, $y^{(i)}$ là đầu ra thực tế của dữ liệu thứ $i$ trong tập huấn luyện. Còn $\sigma^{(i)}$ là kết quả ước lượng được ứng với dữ liệu thứ $i$.
Hàm lỗi của NN cũng tương tự như vậy, chỉ khác là đầu ra của mạng NN có thể có nhiều nút nên khi tính đầu ra ta cũng cần phải tính cho từng nút ra đó. Giả sử số nút ra là $K$ và $y_k$ là đầu ra thực tế của nút thứ $k$, còn $\sigma_k$ là đầu ra ước lượng được cho nút thứ $k$ tương ứng. Khi đó, công thức tính hàm lỗi sẽ thành:
$$ J(\mathbb{W}) = -\frac{1}{m}\sum_{i=1}^m\sum_{k=1}^K\Bigg(y_k^{(i)}\log\Big(\sigma_k^{(i)}\Big)+\Big(1-y_k^{(i)}\Big)\log\Big(1-\sigma_k^{(i)}\Big)\Bigg) $$
Lưu ý rằng, các tham số lúc này không còn đơn thuần là một ma trận nữa mà là một tập của tất cả các ma trận tham số của tất cả các tầng mạng nên tôi biểu diễn nó dưới dạng tập hợp $\mathbb{W}$.
Để tối ưu hàm lỗi ta vẫn sử dụng các phương pháp đạo hàm như đã đề cập ở các bài viết trước. Nhưng việc tính đạo hàm lúc này không đơn thuần như logistic regression bởi để ước lượng được đầu ra ta phải trải qua quá trình lan truyền tiến. Tức là để tính được $\sigma_k$ ta cần một loạt các phép tính liên hợp nhau.
5. Lan truyền ngược và đạo hàm
Để tính đạo hàm của hàm lỗi $\nabla J(\mathbb{W})$ trong mạng NN, ta sử dụng một giải thuật đặc biệt là giải thuật lan truyền ngược (backpropagation). Nhờ có giải thuật được sáng tạo vào năm 1986 này mà mạng NN thực thi hiệu quả được và ứng dụng ngày một nhiều cho tới tận ngày này.
Về cơ bản phương pháp này được dựa theo quy tắc chuỗi đạo hàm của hàm hợp và phép tính ngược đạo hàm để thu được đạo hàm theo tất cả các tham số cùng lúc chỉ với 2 lần duyệt mạng. Tuy nhiên trong bài viết này, tôi chỉ đề cập ngay tới công thức tính toán còn việc chứng minh thì tôi sẽ dành cho các bài tiếp theo.
Giải thuật lan truyền ngược được thực hiện như sau:
1. Lan truyền tiến:
Lần lượt tính các $\mathbf{a}^{(l)}$ từ $l=2\rightarrow L$ theo công thức: $$ \begin{aligned} &\mathbf{z}^{(l)}=\mathbf{W}^{(l)}\cdot\mathbf{a}^{(l-1)} \cr &\mathbf{a}^{(l)}=f(\mathbf{z}^{(l)}) \end{aligned} $$ Trong đó, tầng vào $\mathbf{a}^{(1)}$ chính bằng giá trị vào của mạng $\mathbf{x}$.2. Tính đạo hàm theo $z$ ở tầng ra: $$\dfrac{\partial{J}}{\partial{\mathbf{z}^{(L)}}} = \dfrac{\partial{J}}{\partial{\mathbf{a}^{(L)}}}\dfrac{\partial{\mathbf{a}^{(L)}}}{\partial{\mathbf{z}^{(L)}}}$$ với $\mathbf{a}^{(L)}, \mathbf{z}^{(L)}$ vừa tính được ở bước 1.
3. Lan truyền ngược:
Tính đạo hàm theo $z$ ngược lại từ $l=(L-1)\rightarrow 2$ theo công thức: $$ \begin{aligned} \dfrac{\partial{J}}{\partial{\mathbf{z}^{(l)}}} &= \dfrac{\partial{J}}{\partial{\mathbf{z}^{(l+1)}}}\dfrac{\partial{\mathbf{z}^{(l+1)}}}{\partial{\mathbf{a}^{(l)}}}\dfrac{\partial{\mathbf{a}^{(l)}}}{\partial{\mathbf{z}^{(l)}}} \cr & = \bigg(\big(\mathbf{W}^{(l+1)}\big)^{\intercal}\dfrac{\partial{J}}{\partial{\mathbf{z}^{(l+1)}}}\bigg)\dfrac{\partial{\mathbf{a}^{(l)}}}{\partial{\mathbf{z}^{(l)}}} \end{aligned} $$ với $\mathbf{z}^{(l)}$ tính được ở bước 1 và $\dfrac{\partial{J}}{\partial{\mathbf{z}^{(l+1)}}}$ tính được ở vòng lặp ngay trước.4. Tính đạo hàm:
Tính đạo hàm theo tham số $w$ bằng công thức: $$ \begin{aligned} \dfrac{\partial{J}}{\partial{\mathbf{W}^{(l)}}} &= \dfrac{\partial{J}}{\partial{\mathbf{z}^{(l)}}}\dfrac{\partial{\mathbf{z}^{(l)}}}{\partial{\mathbf{W}^{(l)}}} \cr & = \dfrac{\partial{J}}{\partial{\mathbf{z}^{(l)}}}\big(\mathbf{a}^{(l-1)}\big)^{\intercal} \end{aligned} $$ với $\mathbf{a}^{(l-1)}$ tính được ở bước 1 và $\dfrac{\partial{J}}{\partial{\mathbf{z}^{(l)}}}$ tính được ở bước 3.
6. Tổng kết
Lấy cảm hứng từ mạng nơ-ron sinh học, mạng NN được hình thành từ các tầng nơ-ron nhân tạo. Mạng NN gồm 3 kiểu tầng chính là tầng vào (input layer) biểu diễn cho đầu vào, tầng ra (output layer) biểu diễn cho kết quả đầu ra và tầng ẩn (hidden layer) thể hiện cho các bước suy luận trung gian. Mỗi nơ-ron sẽ nhận tất cả đầu vào từ các nơ-ron ở tầng trước đó và sử dụng một hàm kích hoạt dạng (activation function) phi tuyến như sigmoid, ReLU, tanh để tính toán đầu ra.
Quá trình suy luận từ tầng vào tới tầng ra của mạng NN là quá trình lan truyền tiến (feedforward), tức là đầu vào các nơ-ron tại 1 tầng đều lấy từ kết quả các nơ-ron tầng trước đó mà không có quá trình suy luận ngược lại.
$$ \begin{aligned} \mathbf{z}^{(l+1)} &= \mathbf{W}^{(l+1)}\cdot\mathbf{a}^{(l)} \cr \mathbf{a}^{(l+1)} &= f\big(\mathbf{z}^{(l+1)}\big) \end{aligned} $$
Hàm lỗi của mạng cũng tương tự như logistic regression có dạng cross-entropy, tuy nhiên khác logistic regression ở chỗ mạng NN có nhiều đầu ra nên hàm lỗi cũng phải lấy tổng lỗi của tất cả các đầu ra này:
$$ J(\mathbb{W}) = -\frac{1}{m}\sum_{i=1}^m\sum_{k=1}^K\Bigg(y_k^{(i)}\log\Big(\sigma_k^{(i)}\Big)+\Big(1-y_k^{(i)}\Big)\log\Big(1-\sigma_k^{(i)}\Big)\Bigg) $$
Để tối ưu được hàm lỗi $J(\mathbb{W})$ này người ta sử dụng giải thuật lan truyền ngược (backpropagation) để tính được đạo hàm của hàm lỗi này.
$$ \begin{aligned} \dfrac{\partial{J}}{\partial{\mathbf{z}^{(L)}}} &= \dfrac{\partial{J}}{\partial{\mathbf{a}^{(L)}}}\dfrac{\partial{\mathbf{a}^{(L)}}}{\partial{\mathbf{z}^{(L)}}} \cr \dfrac{\partial{J}}{\partial{\mathbf{z}^{(l)}}} &= \bigg(\big(\mathbf{W}^{(l+1)}\big)^{\intercal}\dfrac{\partial{J}}{\partial{\mathbf{z}^{(l+1)}}}\bigg)\dfrac{\partial{\mathbf{a}^{(l)}}}{\partial{\mathbf{z}^{(l)}}} \cr \dfrac{\partial{J}}{\partial{\mathbf{W}^{(l)}}} &= \dfrac{\partial{J}}{\partial{\mathbf{z}^{(l)}}}\big(\mathbf{a}^{(l-1)}\big)^{\intercal} \end{aligned} $$
Bài viết giới thiệu này cơ bản đã trình bài khái niệm và các lý thuyết cơ bản của một mạng NN, còn cách cài đặt ra sao thì bạn có thể đón đọc ở bài tiếp theo nhé.
